
PRODUCT UPDATES
Introducing the new Performance Measurement Page
Stop staring at accuracy scores. Get one clear verdict per channel: scale, test, or pull back, backed by evidence you can open in one click.

The new Performance Measureent Page in Cassandra answers the only question marketers ask of an MMM on Monday morning: is the model good enough to act on this week, and what should I do with each channel?
It replaces the previous accuracy-led view with a verdict-led one — one sentence at the top, one action per channel, and a single click for every reason to trust the answer.
The Challenge
Marketing teams running an MMM share a recurring problem: the model produces statistical artifacts (accuracy percentages, R², error rates, attribution tables) that are useful to the data team, but don't translate into a Monday morning budget decision.
The deeper problem is multi-source reconciliation. Every channel reports its own ROAS. Lift tests produce a different number. The MMM produces a third. None of those systems takes responsibility for converting the disagreement into a verdict — so the marketer does it manually.
In practice this means:
Three to four hours every Friday rebuilding a self-maintained spreadsheet to pick a defensible number per channel
Weekly anxiety around the Monday board call — "which number do I quote?"
Budget decisions delayed because no single source of truth exists
Loss of trust in the MMM when its output disagrees with platform attribution and the marketer has no way to see why

The Solution: A Verdict-Led Performance Page
The new Performance page reframes everything the model already produces around the marketer's actual workflow. Same model, same data, new presentation. The page is built around three layers, each one click away from the previous:
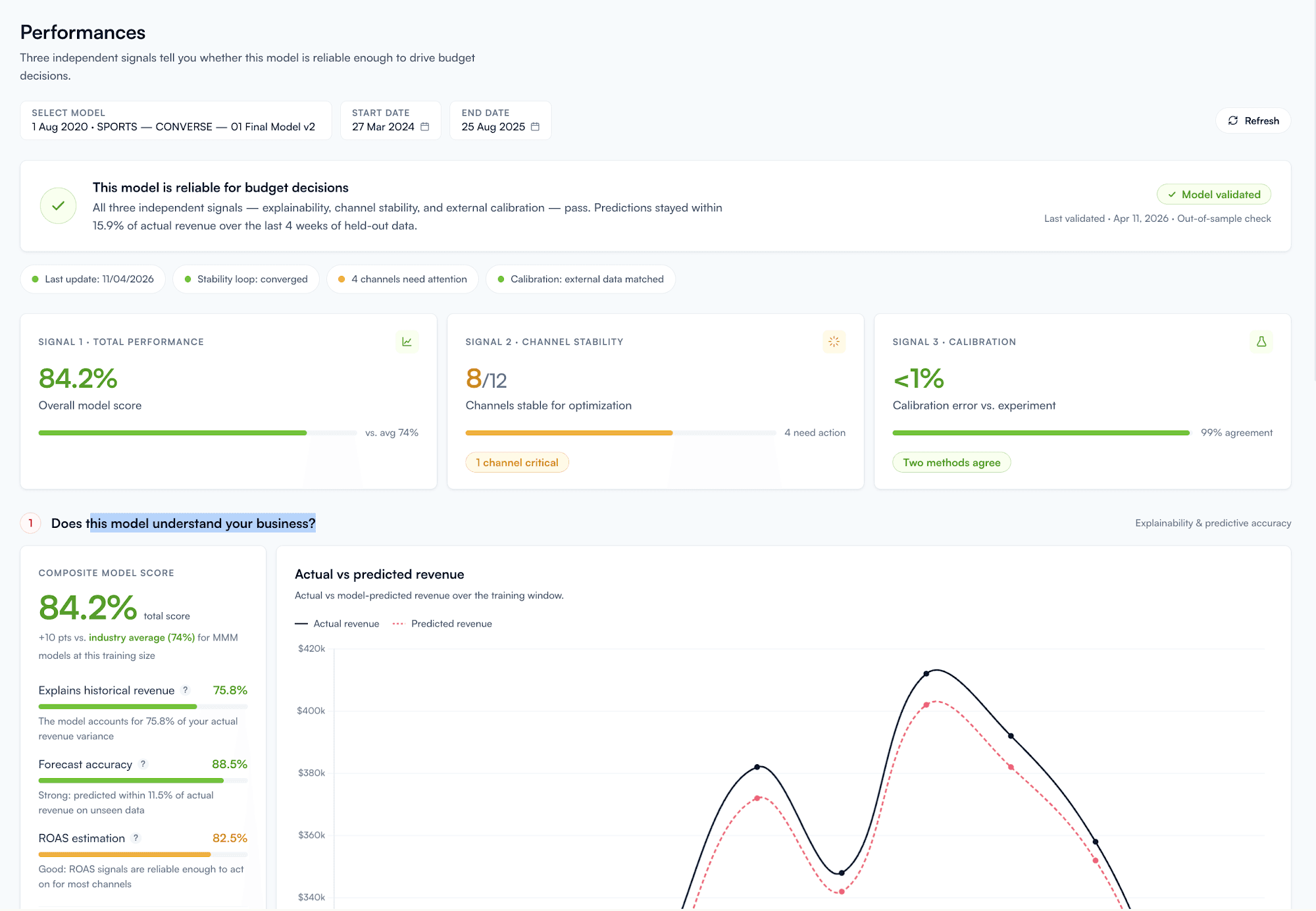
One verdict at the top — a plain-language sentence ("This model is reliable for this week's budget calls" or "Run the model another week") that answers the meta-question before any channel-level detail.
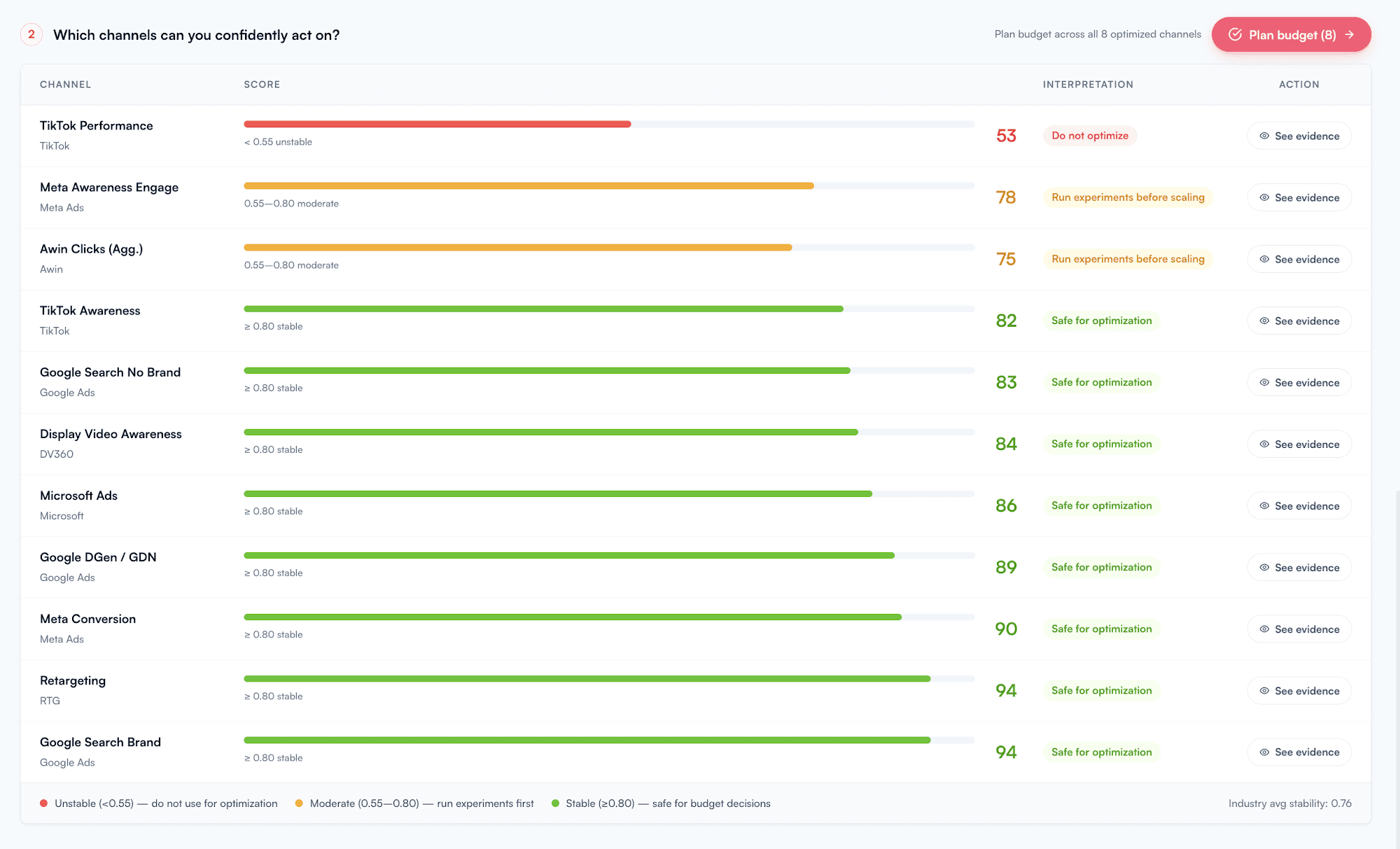
One action per channel — every channel in your media mix gets a confidence score and one of three verdicts: scale safely, run a test first, or don't optimize yet. Color-coded, ordered by confidence.
One click for every reason to trust it — clicking See evidence on any channel opens the Evidence Drawer: a single panel reconciling the channel's own attribution, the most recent lift test, and the MMM iROI estimate, plus stability and calibration history.
This Article Covers:
What's changing — old vs. new Performance page, side-by-side
The three layers — verdict, per-channel action, evidence drawer
The reconciliation engine — how Cassandra picks one number from disagreeing sources
Honest when the model doesn't know — what happens with insufficient data
How to use the new page in your weekly workflow
1. What's changing — Before vs. After
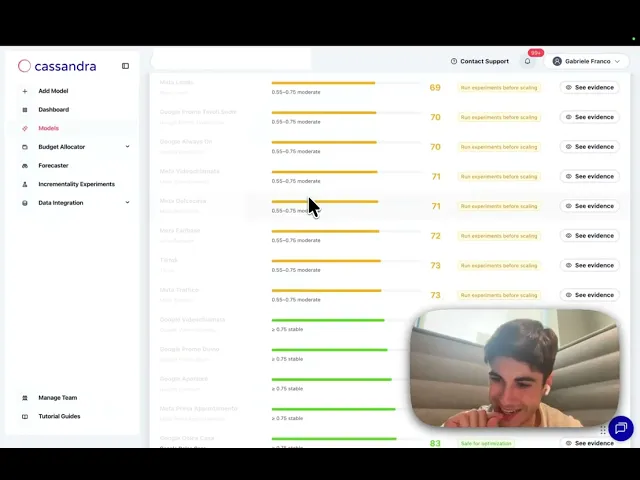
Before: the previous Performance page led with model accuracy (77.4% on the example account) and an attribution table breaking orders down by channel category. Statistically correct, operationally inert. Marketers would read it, nod, and still have to build the Friday spreadsheet to know what to do.
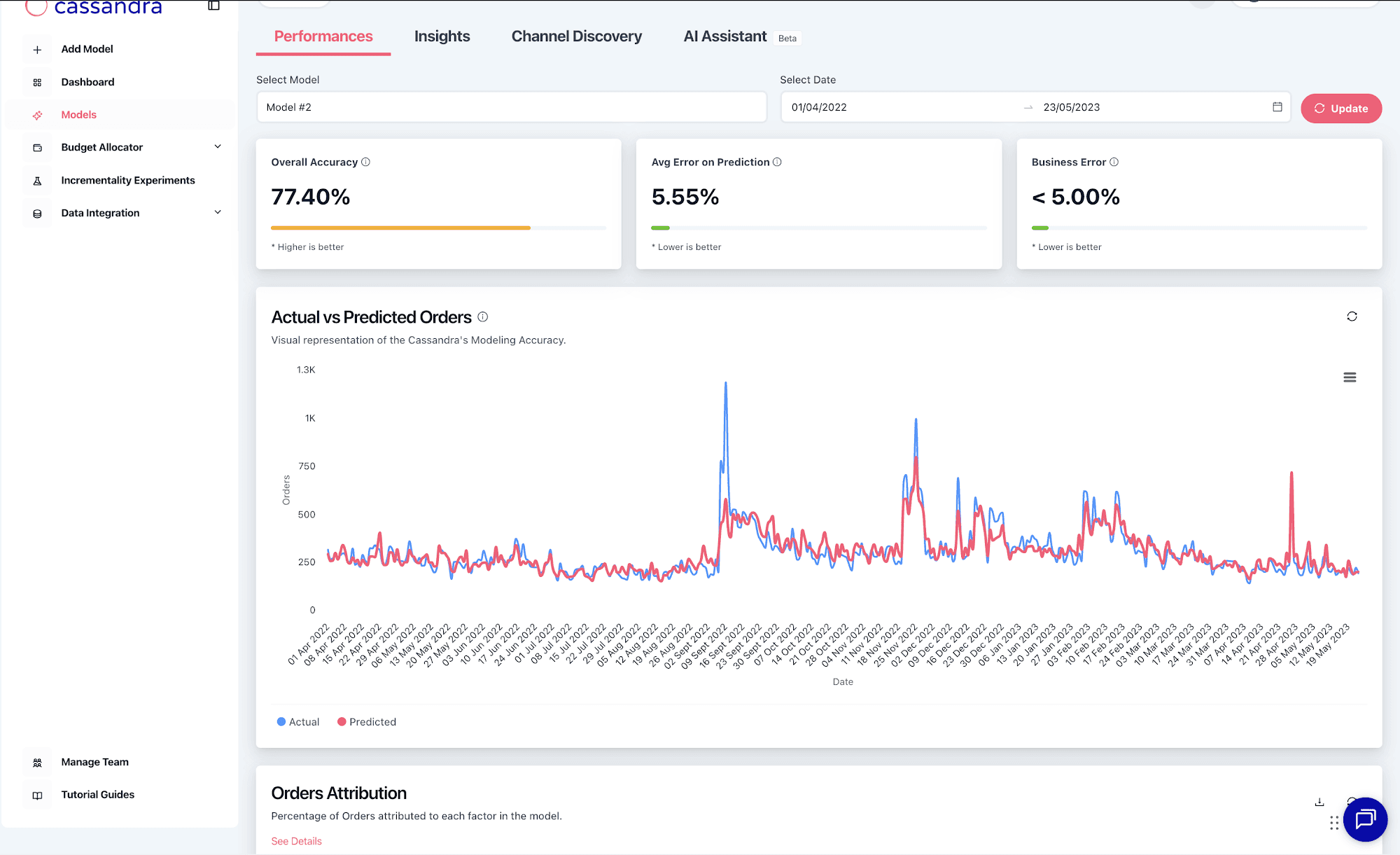
After: the new page leads with a single verdict and three signal cards, then shows every channel with its action. The math is still in the product — just demoted below the answer.
2. The Three Layers
Layer 1 — Verdict. One sentence answering whether the model is reliable enough to act on this week. The verdict updates with each model refresh and reflects three signals together: total performance against historical data, channel-level stability across recent retrains, and calibration against any lift tests on file.
Layer 2 — Per-Channel Action. Every channel in the model gets a confidence score and one of three verdicts:
Scale safely — high confidence, model agrees across measurement methods, recent stability. Add budget here.
Run a test first — moderate confidence, methods partially disagree, or recent volatility. Don't scale until a lift test confirms.
Don't optimize yet — low confidence, divergent measurements, no lift test on file. Pull back or freeze.
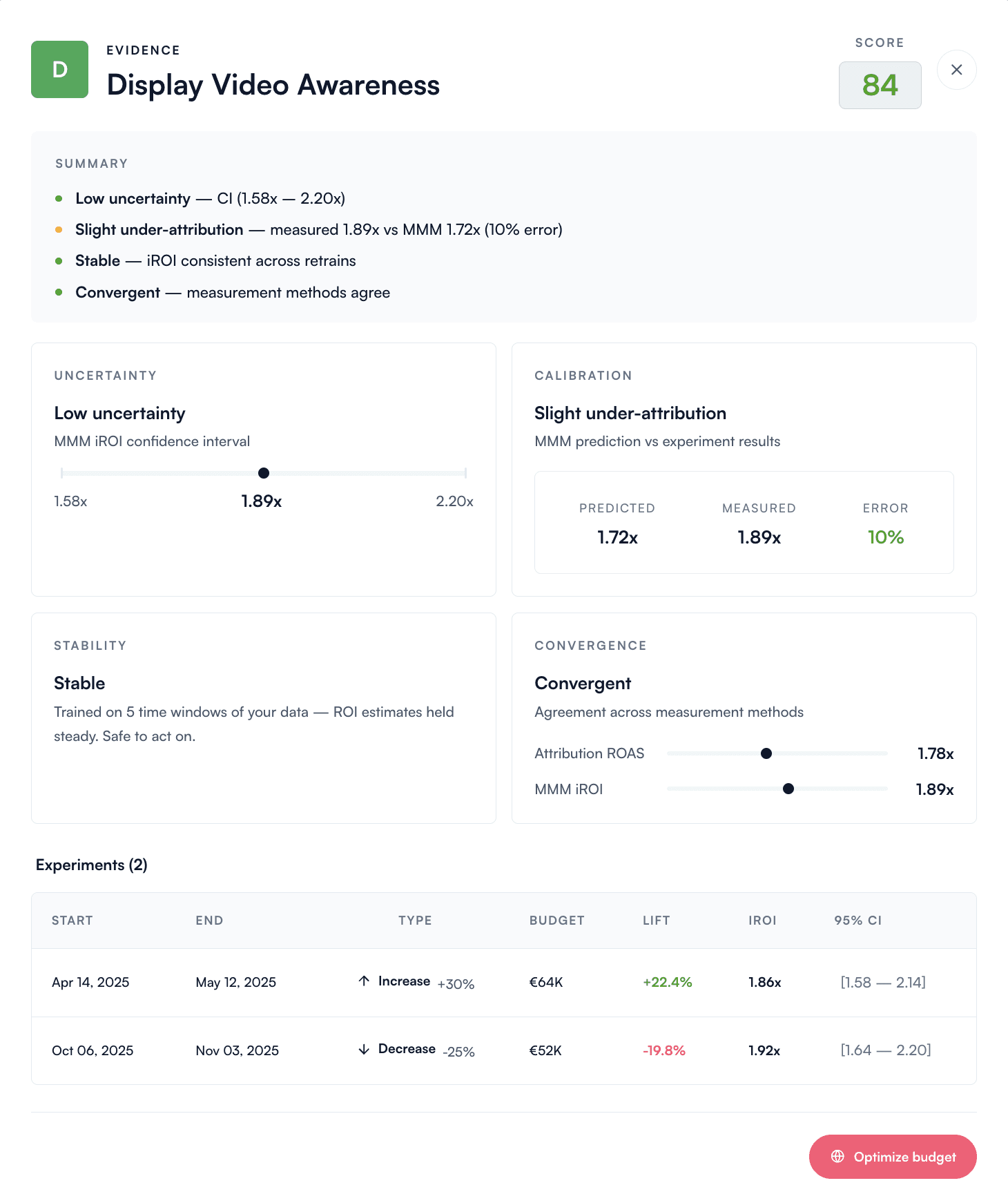
Layer 3 — Evidence Drawer. Click See evidence on any channel to open the panel that contains all the detail behind the verdict. For each channel, the drawer shows:
Uncertainty — the confidence interval around the channel's incremental ROI estimate
Calibration — how the model's prediction compared to the most recent lift test on this channel
Stability — how consistent the iROI estimate has been across recent model retrains
Convergence — side-by-side reading of the channel's own attribution, the most recent lift test, and the MMM iROI estimate
Experiments — every past lift test on this channel, with the result and date
3. The Reconciliation Engine — How it works
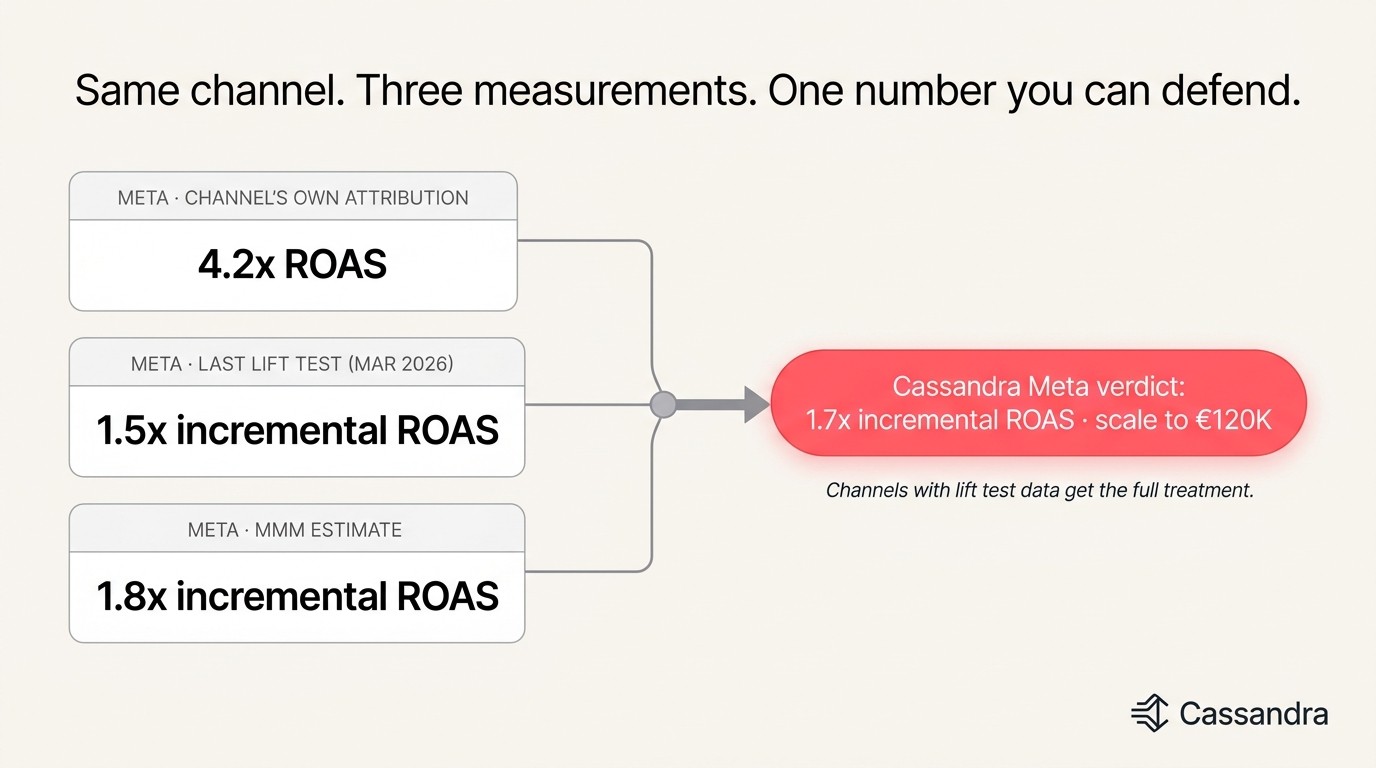
For every channel in your media mix, the new Performance page reconciles three measurement methods into one defensible incremental ROAS:
The channel's own attribution — what Meta Ads, Google Ads, TikTok Ads or your other ad platforms report for that channel
The most recent lift test — your incrementality experiment results for that channel, when one is on file
The MMM iROI estimate — what Cassandra's Bayesian model produces from your full historical media data
Cassandra weights these three sources based on data quality and recency, and produces one verdict per channel. When all three converge, confidence is high. When they disagree, the per-channel verdict reflects the disagreement — and the Evidence Drawer surfaces it so you can investigate before acting.
4. Honest When the Model Doesn't Know
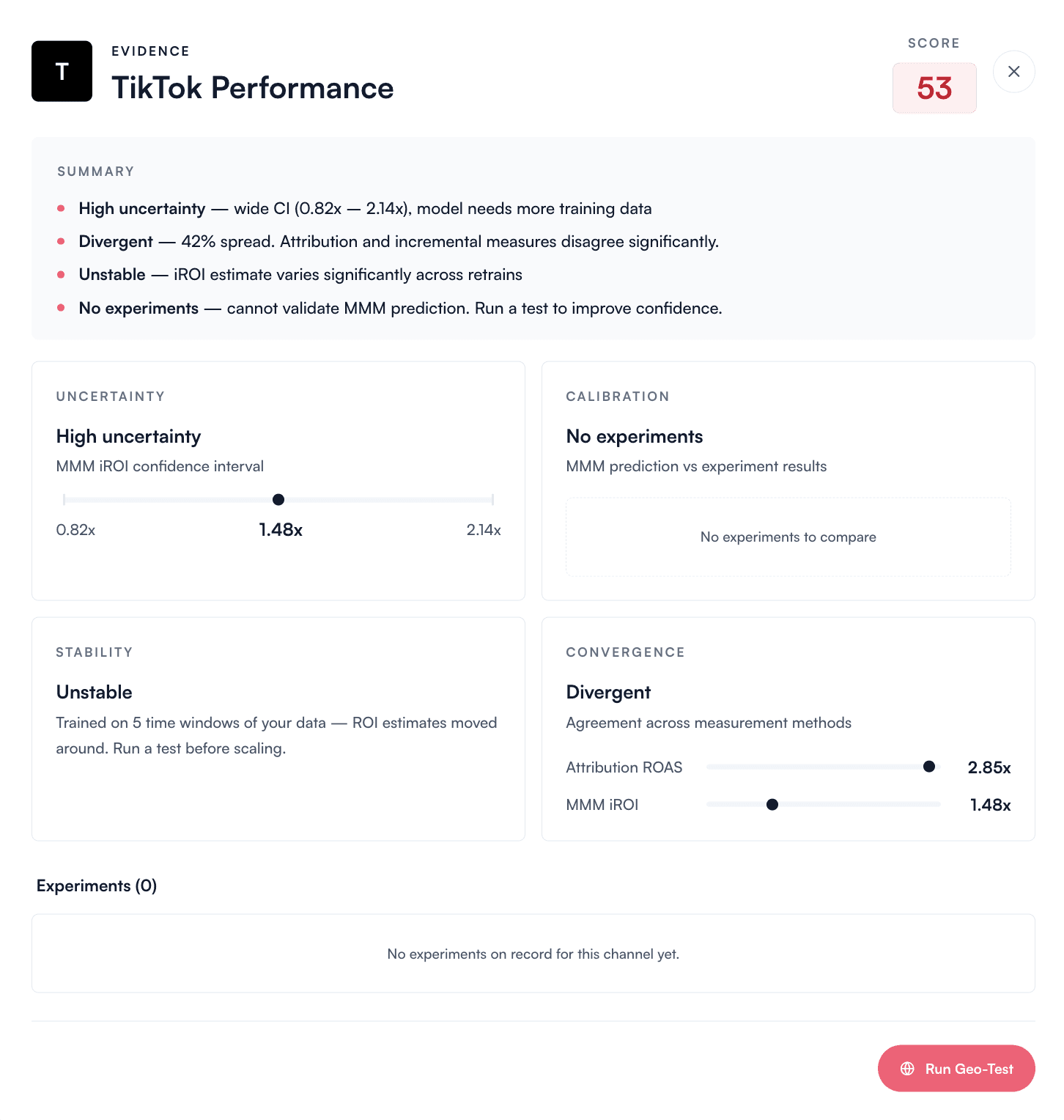
Not every channel has lift test data. Not every channel has been stable for long enough to produce a defensible iROI estimate. Rather than hide that uncertainty behind a confident-looking number, the Performance page flags it directly.
When a channel's confidence score is below the actionable threshold, the verdict is Don't optimize yet, and the Evidence Drawer lists the specific reasons (high uncertainty, divergent measures, no lift test on file). The recommended action is to run a small lift test to unlock confident scaling — not to guess.
A model that can say "I don't know yet" with specific reasons is more useful than one that pretends.
5. How to Use the New Performance Page
Start with the verdict at the top. If the model is reliable for this week's budget calls, you can act on the per-channel scorecard with confidence. If it's not, hold the budget shifts and let the model run another week.
Read the per-channel scorecard top-to-bottom. Channels are ordered by confidence. The green ones are where to add budget. The orange ones are where to test before scaling. The red ones are where to pull back or freeze until a lift test exists.
Click into the Evidence Drawer for any channel before a board call. The drawer is the proof. Take a screenshot of the convergence panel and put it in your slide — that is the audit trail your CFO would have asked for.
Use the "Don't optimize yet" verdicts to design your next lift tests. Each one comes with an estimated test budget. Run those tests, feed the results back, and watch the same channels move from red to green over the following weeks.
Why This Matters for Your Daily Work
Less manual reconciliation. The Friday-afternoon spreadsheet that picks one number from three disagreeing measurement systems is now the default view inside the product.
Faster, more defensible budget decisions. One verdict at the top + one action per channel = a Monday morning budget shift you can ship and defend, without rebuilding a deck from scratch.
Clearer signal on what to test next. Channels with insufficient data are flagged as candidates for a lift test, with a recommended budget. Your test program becomes targeted rather than reactive.
Same model, same math. Nothing about your model changed. The data is the same, the methodology is the same. We changed what you see and what you can do with it.
Available Now
The new Performance page is live for all Cassandra accounts as of today. Open the Performance tab in your account to see the verdict for your current model.
Open the new Performance page →
Book a 15-minute walkthrough if you want one of our modelers to read the verdict on your account with you.