
Marketing Mix Modeling using Python: Auto-tuning for Diminishing Returns and Adstock using Nevergrad
We analyzed the best libraries on the internet to solve this problem and on Facebook Robyn we found a solution: Nevergrad
Marketing Mix Modeling problem
Hi there, if you have ever done Marketing Mix Modeling using python, you probably have encountered in this problem:
you want to transform your media variables with AdStock and Diminishing Returns transformations but the hyperparameters need to be inserted manually.
This manual labor it causes a lot of inaccuracy in most models because humans are biased by their experience, and cannot optimize objectively.
We analyzed the best libraries on the internet to solve this problem and on Facebook Robyn we found a solution: Nevergrad
What is Nevergrad?
Nevergrad is a Python library, developed by Facebook, that uses AI to perform derivative-free and evolutionary optimization.
All these fancy words could scare those who are less experienced with Python and Statistics but don’t be guys. As you’ll see later down this guide, Nevergrad is really easy to use and in just a few lines of code you’ll be able to do your first optimization.
Today we are gonna use it to solve one of the most common problems with Marketing Mix Modeling using python.
Why would I need Nevergrad in MMM?
In Marketing Mix Modeling there are parameters we need to pass to our model in order for it to work. These variables are called Hyperparameters.
An example? Let’s say you want to calculate your media variables’ Adstock and Saturation effects.
Based on the specific formula you’ll use, you’ll generally have to define 2 to 3 hyperparameters per channel.
Now let’s say we are modeling 5 different media channels, plus 2 offline channels.
Not only that but we have a breakdown on the media channels making them a total of 10 channels.
The math is easy: 10 channels, 2 hyperparameters (we’ll make it easy for this one) per channel means you’ll have to define 20 hyperparameters before being able to start the modeling process.
The hyperparams will end up being floating point numbers, between fairly large boundaries, meaning you’ll have a hell lot of fun testing all the possible combinations by yourself randomly.
That’s exactly what Nevergrad is made for: making it easy for you to find the best possible combination of hyperparameters in order to minimize your model error for instance or maximizing its accuracy (that’s really up to you :P).
How does Nevergrad work?
Nevergrad offers a wide range of derivative-free algorithms, including evolution strategies, differential evolution, particle swarm optimization, Cobyla and Bayesian optimization.
To simplify it to its core: you pass a function to Nevergrad which returns a specific value (that could be everything like mape, nrmse or any other KPI that’s important to you) and tell Nevergrad what are the Hyperpameters to optimize.
Then you specify a couple more information such as the algorithm to use and how many trials you want to run and then you let Nevergrad do the work.
Once it has done processing you’ll end up with your set of Hyperparameters nicely optimized.
How does the optimization work? (Optional)
This is an extra section for the more curious ones, feel free to skip to the next one as we won’t talk about Nevergrad specifically here.
In case you are new to the “functions optimization world” you may be wondering what does it actually means and how these algorithms work.
Since this is not the direct topic of this guide, we will keep it short. Consider this just as an introduction to the problem as there’s much more to it and to the different optimization algorithms.
Let’s say we have a function made up of two parameters X and Y which describes the error of our model and imagine being exactly where the red dot is on the function (approximately X = 5, Y = 2).
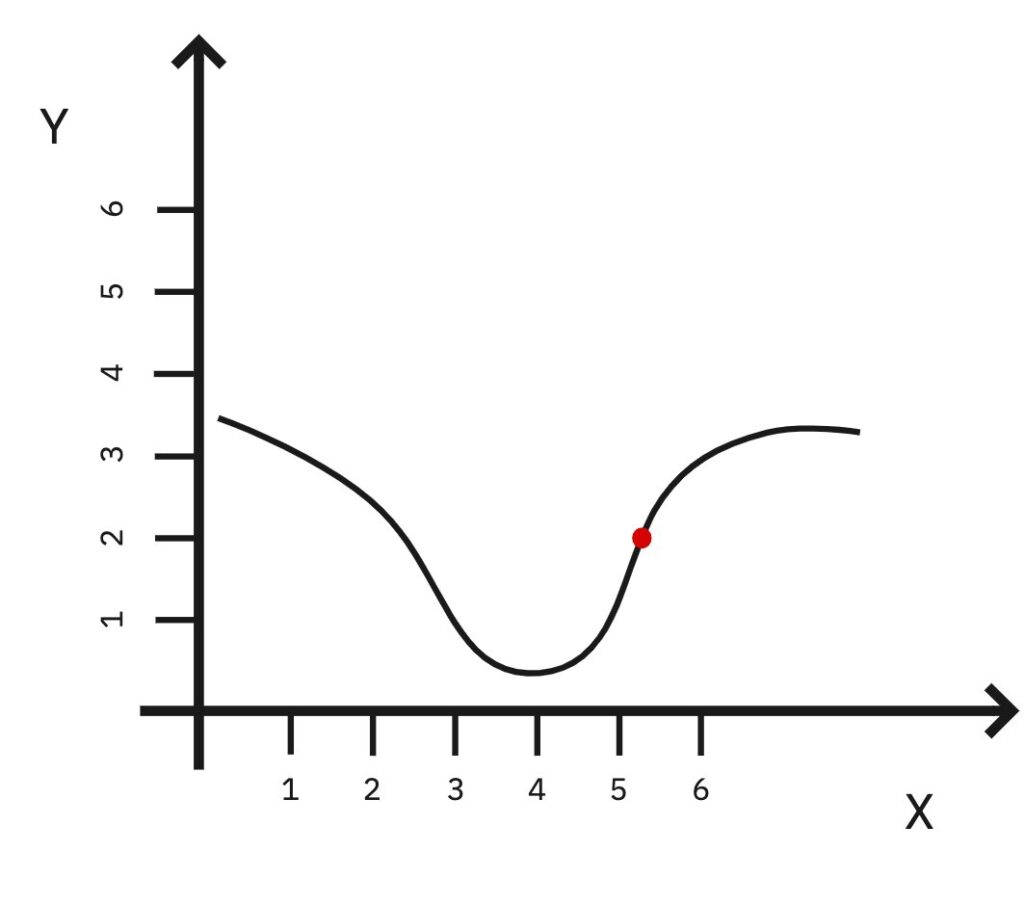
Now let’s say we want to optimize the function in order to minimize the error of our model.
From our position what we could do is take a step in one random direction let’s say X = 6.
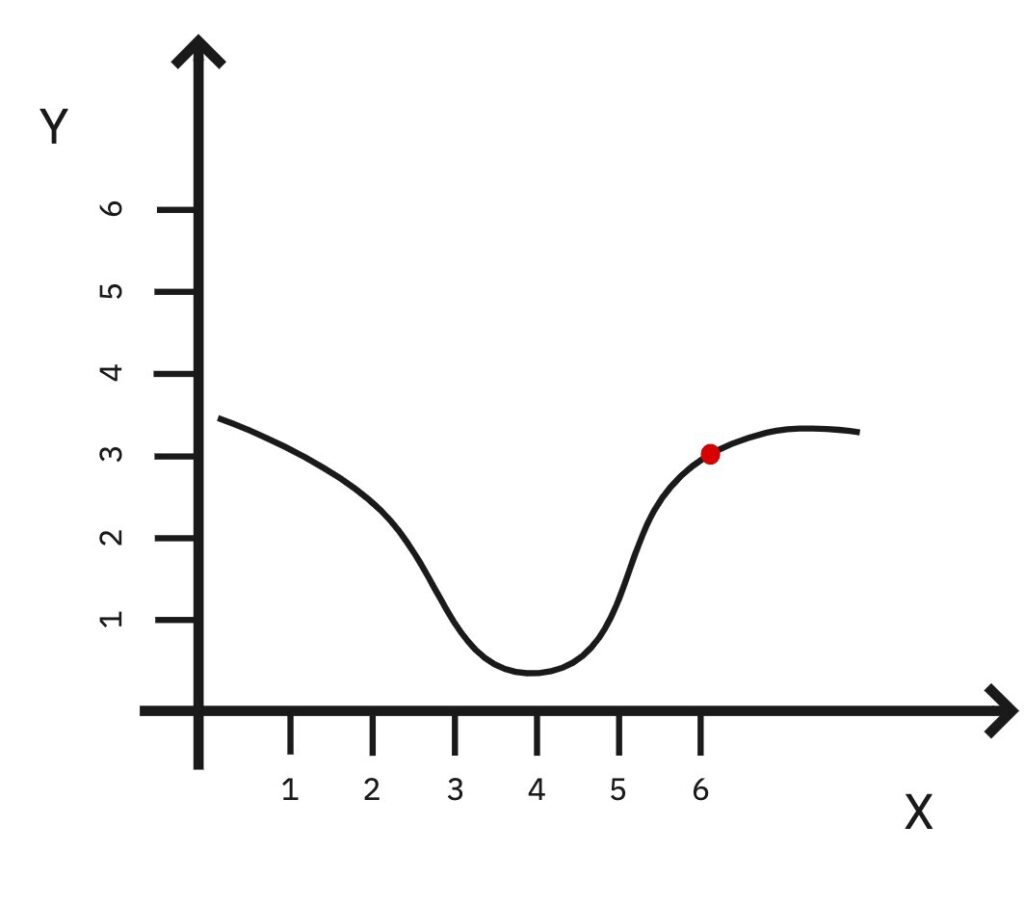
That will make the error higher.
Since we noticed that we will try the other way: X = 4.
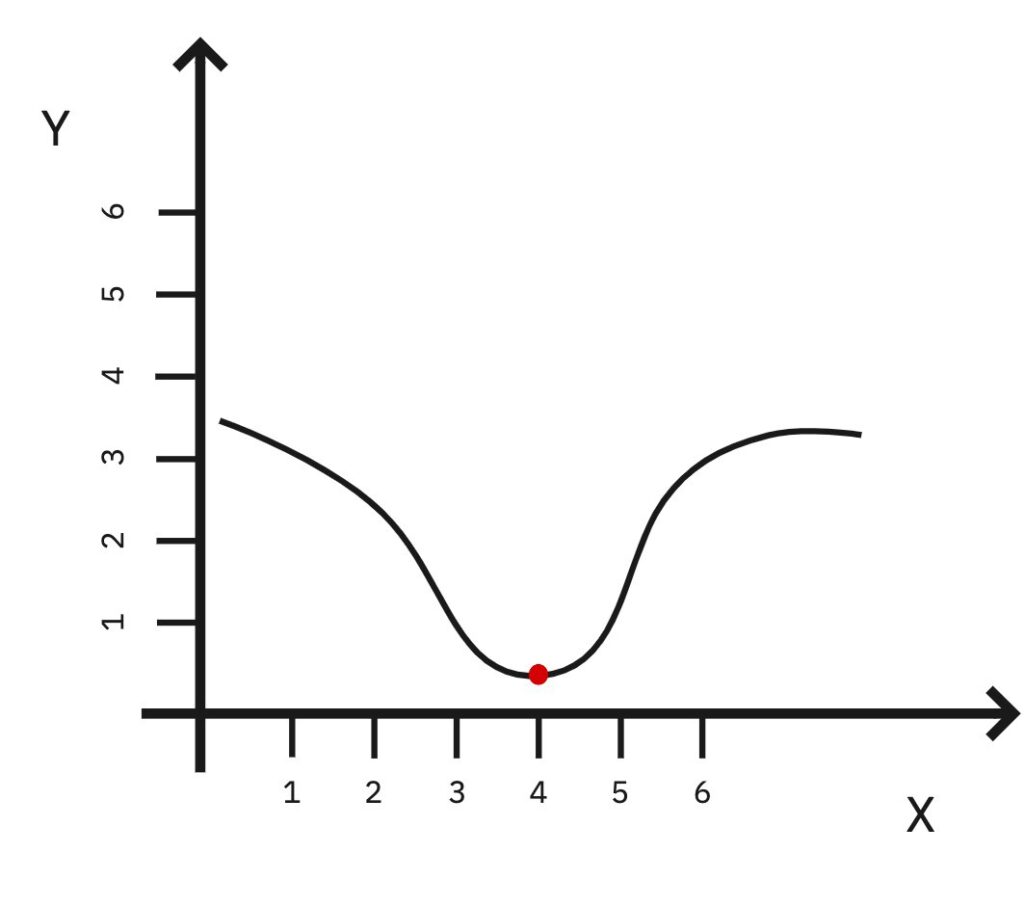
We are going in the right direction!
Let’s keep going X = 3.
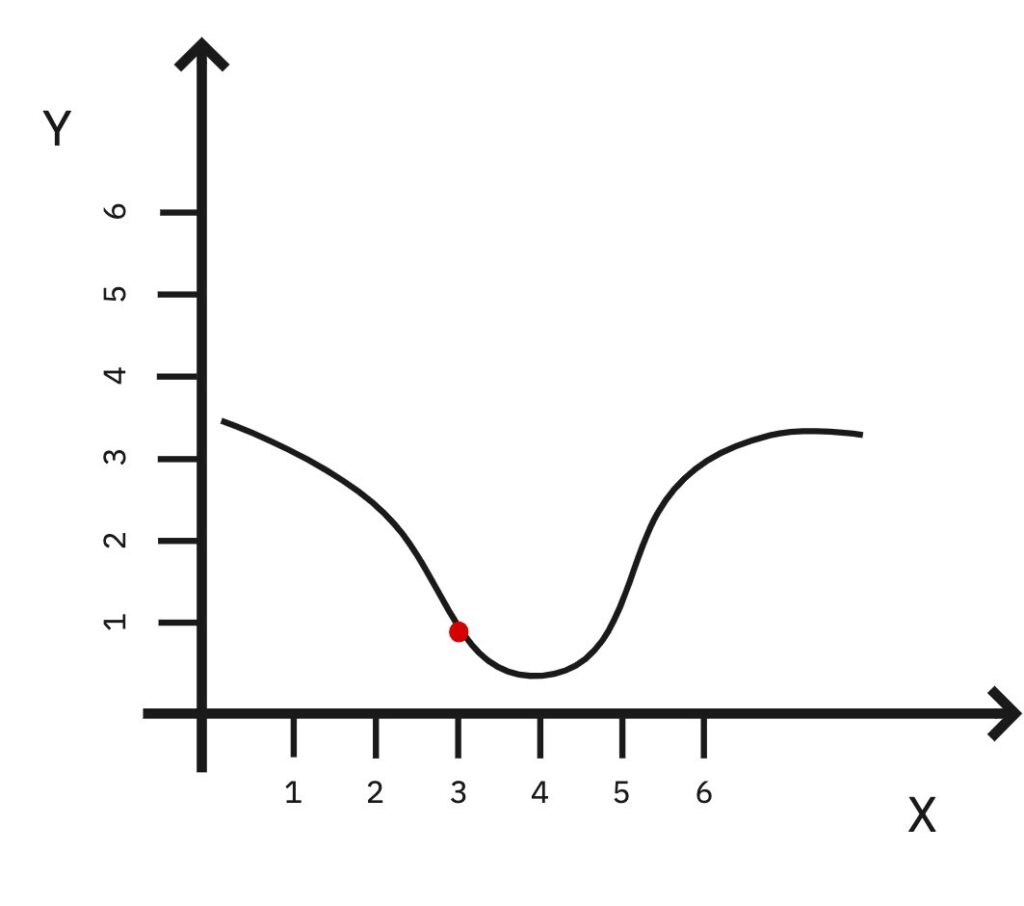
Not working, error is going back up. At this point we could probably stay at X = 4 and call it our “minimum”.
Again: this is an over-simplified explanation and there’s a lot more to it than this.
A great starting point on optimization problems can be this Youtube Playlist.
Back to Nevergrad — Let’s start coding
Let’s say we are modeling for an eCommerce company doing advertising on Facebook (now Meta) and Google.
We know there’s a strong correlation between the variables and for this reason, we decided to use Ridge regression, which better handles multi-collinearity.
Moreover we will use some custom build functions for AdStock and Saturation of the media channels which are declared as follows
import statsmodels.tsa.api as tsa
# Function to return Adstocked variables
def adstock(x, theta):
return tsa.filters.recursive_filter(x, theta)
# Function to return Saturated variables
def saturation(x, beta):
return x ** beta
The variable “x” will be our input to the functions such as our Google Ads’ spent.
The variables “theta” and “beta” are hyperparameters that we should optimize for each media channel differently.
At this point, we want to define one big function containing both Variables Transformations and Ridge Regression. Such function must return the value we want Nevergrad to minimize, in our case it will be the model’s MAPE.
# Create a dictionary to hold transformed columns
new_X = {}
# We define one big function that does all the transformations and modeling
def build_model(alpha, facebook_spend_theta, facebook_spend_beta,
google_spend_theta, google_spend_beta):
# Transform all media variables and set them in the new Dictionary
# Adstock first and Saturation second
new_X["facebook_spend"] = saturation(adstock(df["facebook_spend"], facebook_spend_theta), facebook_spend_beta)
new_X["google_spend"] = saturation(adstock(df["google_spend"], google_spend_theta), google_spend_beta)
# Cast the new dictionary to DataFrame
new_df = pd.DataFrame.from_dict(new_X)
# Append the output column
new_df = new_df.join(df['revenue'])
# Train test split data
X = new_df[spend_var]
y = new_df['revenue']
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Define the model and set the alpha parameter
model = Ridge(alpha=alpha)
# Fit the model using new (transformed) data
model.fit(X_train, y_train)
result = df
# Predict using test data
result['prediction'] = model.predict(X)
# Calculate all model's KPIs
nrmse_val = nrmse(result['revenue'], result['prediction'])
mape_val = mape(result['revenue'], result['prediction'])
rsquared_val =rsquared(result['revenue'], result['prediction'])
# The return must be the value to minimize
return mape_val
# Cast the new dictionary to DataFrame
new_df = pd.DataFrame.from_dict(new_X)
# Append the output column
new_df = new_df.join(df['revenue'])
# Train test split data
X = new_df[spend_var]
y = new_df['revenue']
X_train, X_test, y_train, y_test = train_test_split(X, y)
# Define the model and set the alpha parameter
model = Ridge(alpha=alpha)
# Fit the model using new (transformed) data
model.fit(X_train, y_train)
result = df
# Predict using test data
result['prediction'] = model.predict(X)
# Calculate all model's KPIs
nrmse_val = nrmse(result['revenue'], result['prediction'])
mape_val = mape(result['revenue'], result['prediction'])
rsquared_val =rsquared(result['revenue'], result['prediction'])
# The return must be the value to minimize
return mape_val
Now that everything is set we can start using Nevergrad.
1) If you haven’t installed it already you can use pip (this has to be executed only the very first time)
pip install nevergrad
2) Then, in order to import it, run this line:
import nevergrad as ng
3) Define the Instrumentation object which will contain all of your hyperparameters to optimize
# Define the list of hyperparameters to optimize
# List must be the same as the ones in the function's definition, same order recommended too
instrum = ng.p.Instrumentation(
# Specify the parameter's type as floating number (Scalar)
alpha = ng.p.Scalar()
# You can set lower and/or upper boundaries if needed
facebook_spend_theta = ng.p.Scalar(lower=0, upper=1),
facebook_spend_beta = ng.p.Scalar(lower=0, upper=1),
google_spend_theta = ng.p.Scalar(lower=0, upper=1),
google_spend_beta = ng.p.Scalar(lower=0, upper=1)
)
You can find more information about all the different variable types you can pass to Nevergrad in the documentation.
4) Define the optimizer object. Here you will basically tell Nevergrad how many iterations to run (budget), on which hyperparameters (parametrization) and most importantly you will define the algorithm used.
In the example below we went for NGOpt which is Nevergrad’s meta-optimizer and can be considered the default algorithm basically.
optimizer = ng.optimizers.NGOpt(parametrization=instrum, budget=2500)
If you want to learn more about all the different algorithms available refer to Nevergrad’s Documentation.
5) Run the optimizer by passing to the minimize function, the function we defined earlier, and save the outputs in a new variable.
recommendation = optimizer.minimize(build_model)
Let it do all the hard work for you and then, in the recommendation variable, you’ll find all your optimal hyperparameters for your model.
Extra tip
One extra tip for faster usage of Nevergrad outputs is to redefine our “build_model()” function we built earlier, with more variables in the return like:
return model, nrmse_val, mape_val, accuracy, result
Then by running a line of code like this:
model, model_nrmse, model_mape, model_accuracy, result = build_model(**recommendation.value[1])
You’ll be able to rebuild the whole model using Nevergrad’s optimal hyperparameters and get both the model and all its important KPIs.
All the code of the example above can be found in this GitHub Repository.
Do you want to start with MMM right now? Discover Cassandra MMM
Cassandra is the first self-service software to model your media mix effectiveness on the cloud and receive media plans that maximize your sales.




